现状
早在行业刚开始的那个时期,安全岗位基本只有两种,WEB安全工程师和网络安全工程师,回忆一下近几年企业出现的风险事件、大多是安全工程师围绕应用安全漏洞,以及如何在漏洞攻与防之间进行技术博弈。普遍受限于当时年代对安全的认知,很少有人真正关注到敏感数据对一个企业真正的重要性。
现如今随着GDPR、个人信息安全保护规范等一系列的实施,针对数据泄漏产生的负面影响越来越大,老板们为了能更好的(避)保(免)护(背)公(锅)司数据,数据安全的岗位开始火热了起来,那么数据安全有什么用?

运维角度看数据安全
从安全运营角度来看数据安全建设的必要性,在我们呆过企业中可能会存在这样的对话:
(1) part1
焦躁的安全工程师问到”你你你xxxxURL有个sql注入,赶紧看下,还有哪个应用使用这个库,表里都有哪些敏感字段,有多少受影响的数据量”。业务通常会一脸天真的回复“这个表没什么敏感数据,不重要,我们现在就把泄露处理,敏感数据泄漏通告发给我就行了,别抄给我们领导”。
(2) Part2
焦躁的安全工程师收到来自暗网的监控告警,某某公司几亿订单数据泄漏,来自灵魂的拷问“是有内鬼吧,这是哪个库的数据,这么多敏感字段还是明文,之前某次应急 好像在哪里见到过这种字段,难道上次的SQL注入拖出去这么多数据,md业务还坑我不是敏感数据”。
如果企业安全工程师的日常还经常出现上述类似对话,那么一定还没开始做数据安全方面的建设。
发现&盲区
数据安全第一阶段永远离不开的问题,数据在哪里也就是我们常说的对敏感数据的发现能力?只有知道敏感数据在哪里才能将重要的精力资源投入到需要重点保护的数据资产上。从安全运营的角度思考一下。
(1) part1
秋高气爽的一天Oracle接到一个plsql导出,安全工程师可以直接在数据库审计看到这个plsql导出哪台数据库是什么级别,有什么表,有什么字段、有多少数据量,风险级别直接量化。
这些更准确的信息可以用自动化发单方式(通过邮件、企业微信等方式自动化转发告警通知或者通过SYSLOG\KAFKA方式转发原始日志的形式对接到安全部门)通知到业务告警到安全部,即降低了安全工程师繁琐的排查流程又撕壁和业务一轮轮的四壁扯皮的过程。
(2) Part2
如果某个秋高气爽的一天,你正吃着火锅唱着歌,突然发现暗网出现了疑似数据泄露,通过数据安全平台快速将数据字段进行检索,更快的定位到哪些库存在隐患,这些库对应哪些应用,进行快速的应急响应。
结合安全工程师的分析可以进一步确认受影响的范围,原来毫无头绪的问题突然有了逐渐清晰的解决的方向,不再像之前一样空有一群南拳北斗的“武林高手”跳上擂台却发现找不到像样的兵器、打不出力,一顿花球秀腿后匆匆下场落得台下观众一片奚落。
数据安全
数据安全在数据生命周期内的六个阶段内凭借公司的基建完善程度,安全团队按自己团队的配置,有选择性的选取好下手的环节进行发力,以降低后续安全和业务相互沟通成本、普及数据安全重要性的成本。
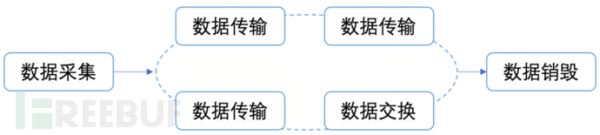
从哪里下手
数据安全的基础的发现能力可以协同DB部门或者从业务侧首先开展,而作为数据安全工程师应该先考虑用何种方式可以达成你的第一个小目标-“具备基础数据在哪的发现能力”,从DB部门切入可以更快的实现安全部门与db部门的协同工作闭环运营,主要因为db部有你需要的数据资源,安全部有数据分类分级使用上的需求分析能力,二者相结果,可以最短路径实现数据安全运营落地闭环。
主动发现数据
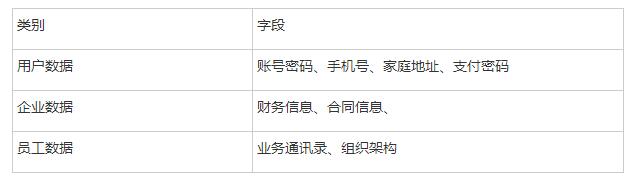
从上至下,从安全委员会推到业务线和数据组建立完善的线上数据库制度流程,统一的分类分级标准,数据级别方面数据分级大致可以按用户的数据属性来划分,比如用户信息类、企业信息类、商户信息类
按类别分类
对数据进行动态识别、识别的方式有很多,例如静态规则、机器学习,目标是不断完善敏感数据的识别率,最简单的可以直接去遍历所有的库表结构字段、遍历集中日志存储中心,对不同的应用,不同的数据库表中存在哪些敏感数据进行自动化审计。
线下通过数据安全团队对离线分析数据进行分类分级生成库表级别画像,可以完善出一套基础的“数据资产”图谱,有了图谱权限管理、审计都可以逐步开展,当然发现能力,数据资产也不止这一个维度,需要多维度共同作用构成。
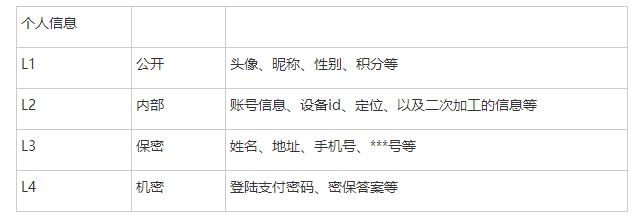
安全团队做到了实时的线上线下敏感数据采集发现,那么下一步就很清晰了,对数据进行分类分级重点关注L3,L4级个人敏感信息、公司级别敏感信息、对敏感数据进行落地脱敏存储、权限审计、数据库加解密等。
更多的是场景
更多的是场景问题,数据溯源,场景的数据溯源过程大致如下,数据样本收集、数据样本特征分析(定位泄漏时间、定位字段、定位数量)确认泄漏源、确认泄漏应用,我们需要从海量的数据中提取特征,比如本批次泄漏字段有哪些,该字段同时存在与哪些库表,隶属于哪几个应用。依次定位调用时间、调用库表、调用应用。
围绕数据泄漏的不同场景,安全工程师会有意的向加工数据增加一些“染色数据”,增加“染色数据”的好处在于方便数据审计、方便数据溯源采集特征。
对二次存储分析使用的离线数据进行加密各种的数据脱敏(数据染色),二次使用的数据进行染色大致原则可以这样理解,将数据重新生成,但不影响原有业务开展数据统计分的析结果,例如业务提出的需求“我们需要最近24小时订单分析每个地区的下单情况”,
安全工程师需要对此需求进行提炼,提炼后的业务真实想要的需求是“业务需要订单转化比率,关注的是总体的比例,是在统计一批数据的百分比,但不关注某一字段的准确性,”例如小明使用的是联通手机号185123123123,我们在保持联通的属性185不变后续几位可以转换为“0”即185123000、住所地址保留市区街道不变具体楼单号进行染色、一批数据的性别比例染色,保持原有的男女比例不变,这样这批数据在提供给业务侧进行统计分析的时候不会产生影响,同时可以保障用户数据的安全性。 这些都属于数据染色区别在于不同应用场景。
小结
开展数据安全工作上踩过很多坑,总结总结,无非是受限于老三样,安全部规模,基建程度,老板关注度(是否出过事),比如在数据分散且没有统一的数据总线情况下最好不要异想天开的先去做什么权限管理,优先考虑那些能占用资源少且能闭环运营的工作,如做自动化分类分级打标、加脱敏等,不断迭代安全部对数据安全方面的能力,丰富企业常见的数据安全场景的解决方案能力,再去啃标识化染色权限管理未尝不是也是一种不错的选择。

Copyright © 2005-2017 京ICP备06011561号-1 citwb.com All Rights Reserved. 北京艾锑无限科技发展有限公司 版权所有
阿里生态伙伴| 国家高新企业 | 中关村高新企业 | 企业安全联盟会员 | 六大软件著作权 | 全国IT外包| | 网站地图

 微信扫一扫
微信扫一扫